Your juniors aren't learning
Legal training worked through proximity, observation, and correction. All three are breaking. Lorna Khemraz investigates.


Every legal team I speak to is using AI. Almost none are asking what it's doing to their junior lawyers.
My last piece was about the onboarding most teams skip. This one goes deeper: what happens when the training mechanism itself breaks.
Something new is coming up: Starting this Friday, we're launching weekly briefings on what's moving in legal tech.
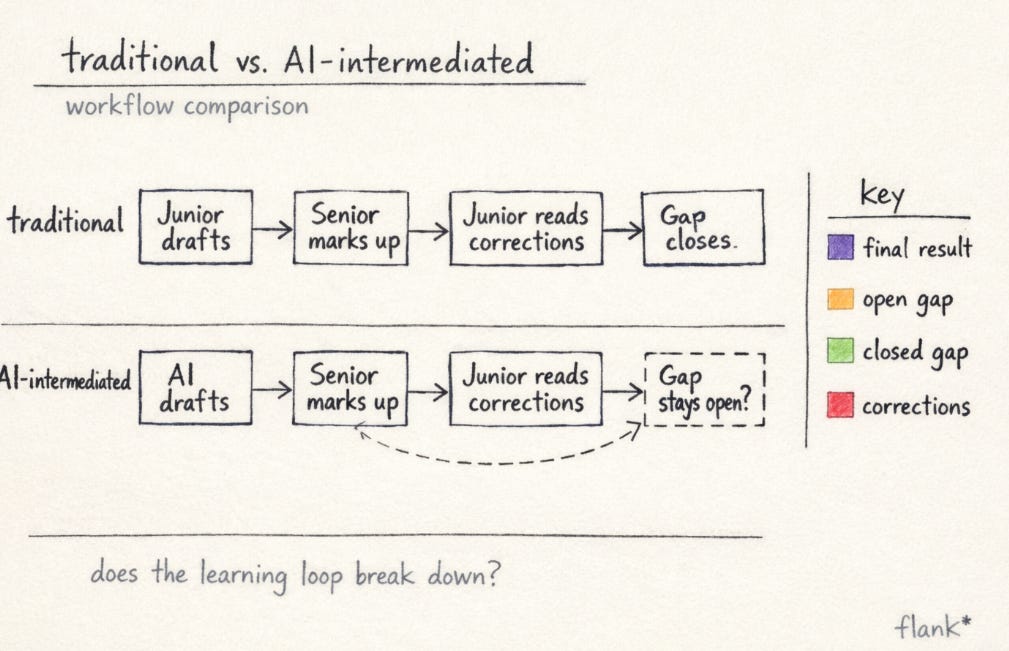
The rite of passage that stopped working
The way legal training actually works, or worked, is not especially mysterious once you describe it. A junior lawyer joins a team. For the first several months, they spend a significant portion of their time watching. They sit in on calls. They read correspondence between a senior and a client and absorb, without being told to, the register and the judgement that shapes it. They draft a position paper, it comes back covered in tracked changes, and the act of reading those changes, not just accepting them but understanding why each one was made, is the substance of the education.
In private practice, the scrutiny is relentless and the process is legible. You do the work, someone marks it up, you understand the gap between what you produced and what they needed. Repeat, until the gap closes. In-house, the process is softer but functionally similar. A GC who runs a tight shop knows which junior has a feel for commercial risk and which one doesn’t, because they have watched them navigate enough situations to have evidence. The feedback may be less formal, but it is continuous, and the mechanism is the same: judgement transferred between people through proximity, observation, and correction.
You do the work, someone marks it up, you understand the gap between what you produced and what they needed. Repeat, until the gap closes.
This system has real flaws. It reproduces existing ways of thinking more readily than it generates new ones. It advantages people who are visible, confident, and in the room, which tends to correlate with other things that have nothing to do with legal aptitude. Still, within those limits, the mechanism worked. Legal knowledge moved between people because people spent time together, observing and correcting each other’s reasoning in real situations with real stakes.
What has changed in the past two to three years is not that junior lawyers are less talented. I don’t think that is true. What has changed is that the mechanism has broken.
🔍 The feedback is going to the wrong place
Here is roughly what now happens. A junior lawyer is asked to review a supplier contract, or to draft a quick advice note for a business partner asking whether a new commercial arrangement triggers a data processing obligation. They open a general AI assistant, describe the task, paste in the relevant text, and receive back something that looks like an answer: structured, apparently thorough, covering the standard ground. They tidy it up, adjust the framing slightly, add their name, and send it to the senior.
The senior receives the document. They recognise almost immediately that most of the substance came from a general AI, not because the junior told them, but because it reads like something assembled from first principles rather than from any knowledge of how this team operates. The contract markup flags standard positions on liability caps and IP assignment without any sense of which positions this counterparty typically pushes back on, or which ones the GC has already decided are not worth fighting for. The advice note is technically accurate but framed like a law firm memo: the register is wrong, the risk calibration is abstract, and it tells the business partner what the law says rather than what they should do. They mark it up. The junior reads the markup.
This is where the mechanism breaks. The corrections are now addressed to a process that the junior did not run, and to a system that holds none of the context that would have made the output useful. The senior is giving feedback to the model, via the junior, who is the intermediary but not the author. The gap the feedback is supposed to close is not between what the junior understood and what they should have understood. It is between what a general AI produces and what a lawyer with institutional knowledge would produce, and that gap is not the junior’s to close through thinking and practice. It can only be closed by changing the tool, or by building the institutional context into the system the junior is using, which is a different kind of work entirely.
The senior is giving feedback to the model, via the junior, who is the intermediary but not the author.
This is not a criticism of using AI. The assistant probably made the first draft faster. The question is what happens to the junior lawyer across ten or twenty of these engagements. The traditional mechanism was iterative. You got better at the thing you were doing because you were doing it and receiving feedback on your actual decisions. If AI is consistently doing the substantive analysis, the junior is being trained, slowly, in a different skill set: reading AI output critically, identifying where the model is wrong, communicating the model’s conclusions in a useful format. Those are real skills. But they are not the same as developing legal judgement, and I think most senior lawyers who are being honest about it have started to notice the difference.
The degradation you won't see until it's too late
The research on human performance in automated systems makes a related point. When people move from active execution to monitoring a system that executes on their behalf, their understanding of the underlying task degrades over time. The failure modes of an AI legal assistant are less catastrophic than those of cockpit automation, but the degradation mechanism is the same. If the junior lawyer is not practising the underlying task, they are not developing the capability to evaluate or improve the system doing the task on their behalf.
If the junior lawyer is not practicing the underlying task, they are not developing the capability to evaluate or improve the system doing the task on their behalf.
What makes this harder to address is that the degradation is invisible in the short run. The AI-assisted output passes the senior’s review, or passes it well enough. The deal closes. The metric that would reveal the junior’s slower development, genuine independent legal judgement, does not show up in any standard measure of productivity or output quality. It shows up years later, when a junior who has spent three years as an AI intermediary rather than a legal thinker is suddenly expected to handle work that requires independent judgement, and finds they have less of it than their experience level implies they should have.
If the junior lawyer is not practising the underlying task, they are not developing the capability to evaluate or improve the system doing the task on their behalf.
🏗️ A crutch is not the same as a system you own
The obvious response is to reintroduce manual drafting exercises: have juniors produce their own analysis before looking at the AI output, or produce a version entirely without assistance. This is probably necessary. But I think it addresses only part of the problem, and possibly the less important part.
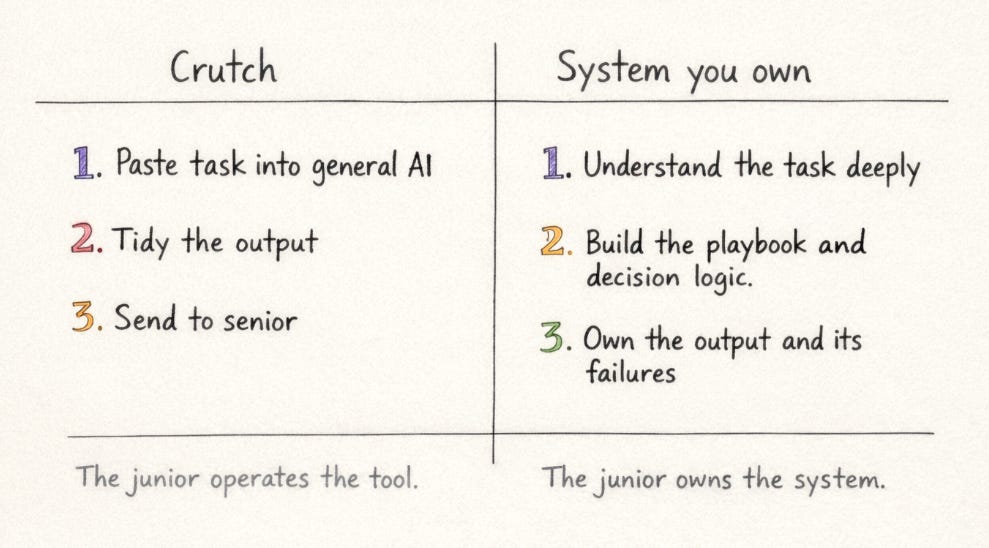
There is a more fundamental distinction that the conversation about legal AI has been slow to name clearly, between AI as assistive technology and AI as automation. Most junior lawyers using AI today are in the first category. They are using general assistants as a kind of prosthetic: paste in the contract, get back a list of issues; paste in the facts, get back an advice note skeleton. The AI props up the output. It does not replace the need for the lawyer to eventually know what good looks like, but in practice it defers that reckoning indefinitely, because the output is usually good enough to pass, and “good enough to pass” is not the same as “produced by someone developing competence.”
The crutch metaphor is deliberately unflattering, but I think it is accurate. A crutch means you never rebuild the muscle. The capability the crutch is compensating for atrophies rather than develops. And when the crutch is removed, or wrong for the situation, or confidently producing something incorrect in a context where you lack the judgment to catch it, you have nothing to fall back on.
Automation is a different relationship entirely. To automate a task effectively, you have to have already understood it well enough to encode your judgment into a system: what the inputs are, what the decision logic should be, where the edge cases live, what should trigger escalation and what should not. You cannot automate what you do not understand. This is not a limitation of the technology. It is a property of what automation actually is. A contract review agent built on a properly configured playbook is not doing something the lawyer cannot do. It is doing something the lawyer understands well enough to have specified, and is now executing at a scale and speed the lawyer cannot match manually. The agent is an extension of the lawyer’s judgment, not a substitute for it.
Most of what I see in practice is neither of those things. Juniors using horizontal tools: general AI assistants with no knowledge of the team’s risk appetite, no playbook, no understanding of how the GC calibrates an advice note for a particular business partner versus a formal external position. These tools are not the same as a configured system built on the team’s actual positions and communication norms. Treating them as equivalent, or conflating “using AI” with “using a system grounded in institutional knowledge,” is how organisations end up with both a training problem and an output quality problem simultaneously, and mistake the second for a technology limitation rather than a knowledge gap.
You cannot automate what you do not understand.
Telling a junior lawyer to use AI responsibly, without making them responsible for understanding the difference between a crutch and a system they own, reproduces the same pattern. The AI remains external. The junior remains its operator. The relationship has not changed, and the capability required to change it, understanding the work well enough to automate it rather than offload it, is not being built.
What I am arguing for is closer to authorship than operation. The junior is accountable for the system’s outputs in the same way they would be accountable for a first draft they wrote themselves. When the system produces something wrong, the question is not “why did the AI get that wrong” but “why was I running a system that would produce that output in this context, and what am I going to do about it.” That posture only makes sense if the junior has enough underlying knowledge to diagnose the failure. Which means the goal of training is not to delay AI use, but to develop the capability that makes AI use something other than dependency.
⚖️ Accountability requires the judgement the training was building
This matters beyond individual development, and I think the connection is worth making explicit.
One of the persistent blockers for agentic AI becoming genuinely embedded in enterprise legal operations, as opposed to being used on a tool-by-tool basis by individual lawyers, is the question of accountability. When an AI agent handles a contract request from end to end, picks it up from the shared inbox, reviews it against the playbook, and sends back a markup, without a lawyer reading every line before it goes out, someone needs to be accountable for the quality and risk profile of that output. In most organisations, the answer to “who is accountable” is either undefined or defaults uncomfortably to the legal team in aggregate, which means nobody in particular.
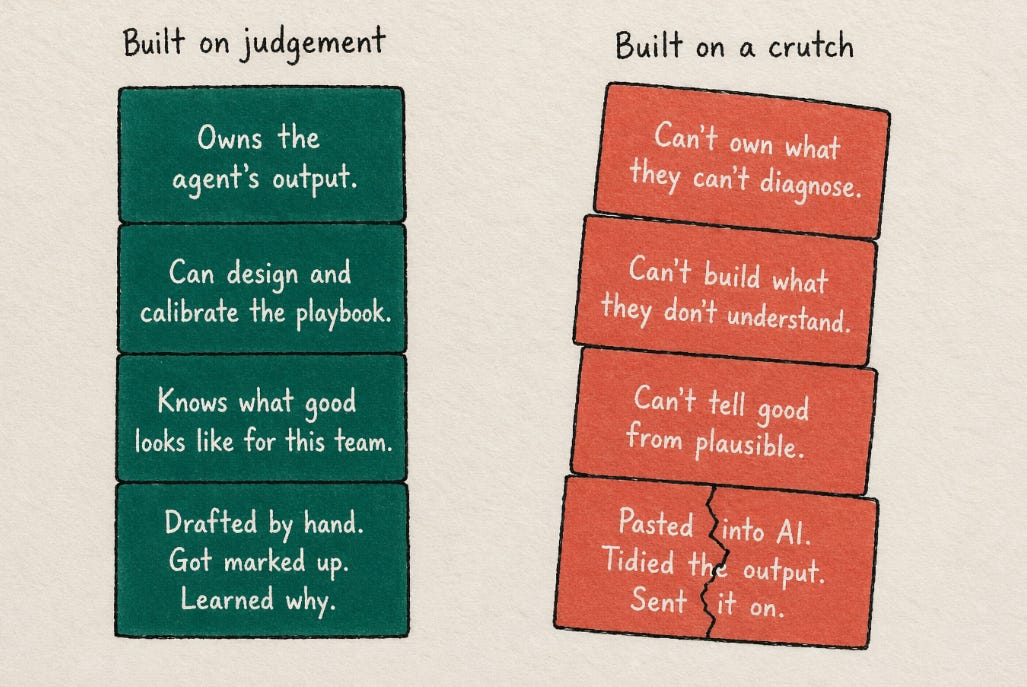
What makes agentic deployment actually work in practice, looking at the deployments that hold up over time rather than the ones that get quietly wound back, is that someone on the legal team owns the system. Not just in the sense of having admin access, but in the sense of understanding how it behaves, where its reasoning is reliable and where it is not, what the playbook says and why, and what should trigger human review versus autonomous execution. That person is accountable for the system’s output the way a lawyer is accountable for the advice that goes out under their name.
The skills that the traditional training system was building turn out to be prerequisites for the accountability that agentic deployment requires
If that accountability structure is built into how legal teams think about deploying agents, including which team members are responsible for which systems and what responsibility for a system actually entails, it changes what the development of junior lawyers needs to look like. Accountability for an AI system, in any meaningful sense, requires the kind of underlying judgement the system is trying to replicate. You cannot calibrate a playbook if you do not understand the law well enough to know what good playbook reasoning looks like. You cannot identify the failure modes of a contract review agent without having reviewed enough contracts by hand to have a model of what a correct analysis should contain. You cannot own an agent that drafts advice notes without knowing what a well-calibrated advice note looks like for this team, with this GC’s risk tolerance, for this category of internal client.
The skills that the traditional training system was building turn out to be prerequisites for the accountability that agentic deployment requires. Which is one reason, I think, that the teams finding it hardest to deploy agents with confidence are often the same teams where junior development has moved fastest toward AI-intermediated output.
The gap between adoption and results
The market shift in the past year has been striking. The dominant question from legal teams has moved from “can AI actually do this?” to “what can it actually do?” The disbelief phase is largely over. ACC data from early 2026 puts corporate legal AI adoption at 52%, up from 23% the previous year. But the same data shows that only 7% of teams have actually reduced their outside counsel spend. The gap between those two numbers, between adopting AI and getting structurally different results from it, is I think the same gap as the one I am describing in legal training. Using the tool is not the same as owning the system.
What I am genuinely uncertain about is the timeline. The change in training conditions has happened fast, and the feedback cycle that would reveal its consequences, lawyers reaching senior level with a judgement deficit they do not know they have, runs over years, not months. There is no near-term signal that would clearly indicate the problem is as significant as I think it is, which makes it easy to defer.
But the teams that start now, building junior lawyers who understand the work well enough to automate it rather than just offload it, will be in a materially different position from those who do not. The junior lawyer who has spent two years owning a configured system, improving it, understanding its failure modes, and being responsible for its output, is not just a better user of AI. They are someone who can extend that system further, deploy it with more confidence, and explain to a GC exactly why it should be trusted in a particular context. That is the person who makes agentic AI actually work at the organisational level, because they hold the accountability that distributed crutch-use can never produce.
The rite of passage that needs reinventing is not, I think, the markup itself. The markup was always just the mechanism. What it was for was the transfer of accountability from someone who knows, to someone who is learning to know. That transfer still needs to happen. It is just that the thing the junior lawyer now needs to know, well enough to be accountable for it, is both the law and the system running on their behalf. Those are not separable. You cannot own the second without the first.
✳️
 | A guest post by
|